robots.txt文件站长们应该都不陌生,正确的robots.txt文件对于网站来说是非常重要的,作用是告诉搜索网站哪些地方可以抓取,哪些地方不可以抓取。
“wordpress网站如何建立robots.txt文件”这篇文章详细介绍过wordpress网站robots.txt文件,大家可以先看看这篇文章,以便于能更好的理解robots.txt文件。
robots.txt文件虽然简单但也是极易出错的,一个字符的错误就会影响整个网页收录效果,阻止搜索引擎索引网站页面,robots.txt文件错误率非常高,即使是经验丰富的网站优化人员也避免不了。
你认真理解完这篇文章将可以学到以下内容:
1、robots.txt文件是什么;
2、robots.txt长什么样;
3、robots.txt用户代理和指令;
4、网站什么时候你需要robots.txt文件;
5、如何找到网站robots.txt文件;
6、如何建立一个robots.txt文件;
7、robots.txt的写法;
8、robots.txt文件示例;
9、如何检测robots.txt文件中的问题。
robots.txt文件是什么?
robots.txt文件是搜索引擎抓取网站的第一个文件,作用是告诉搜索蜘蛛网站哪些页面可以抓取,哪些页面不可以抓取,robots.txt文件规则中列出了所有禁止或允许搜索蜘蛛抓取的网站页面,还规定了搜索蜘蛛(非Google谷歌搜索)该怎样抓取网站内容。
重要提示:
大部搜索蜘蛛都会遵守robots.txt文件规则,而有少部分搜索蜘蛛则无视robots.txt文件规则,百度和谷歌搜索都会遵守robots.txt文件规则。
Robots.txt长什么样?
以下这网站robots.txt文件基本格式:
Sitemap: [URL location of sitemap]
User-agent: [bot identifier]
[directive 1]
[directive 2]
[directive …]
User-agent: [another bot identifier]
[directive 1]
[directive 2]
[directive …]
如果你以前没有了解过robots.txt文件,你初次看它可能会觉得很难,但其实只要弄懂了robots.txt文件语法格式就非常简单了,简单地讲你可以在robots.txt文件中规则搜索蜘蛛网站哪些页面可以抓取,哪些页面不可以抓取,下面大兵来给大家详细介绍下。
User-agents(用户代理)
每个搜索引擎都有一个特定的用户代理,可在网站robots.txt文件中针对不同的用户代理分配不同的抓取规则,搜索引擎用户代理大概有上百种,以下是对网站SEO优化有用的用户代理:
Google: Googlebot
Google Images: Googlebot-Image
Bing: Bingbot
Yahoo: Slurp
Baidu: Baiduspider
DuckDuckGo: DuckDuckBot
robots.txt文件中所有用户代理均严格区分大小写,但你也可以使用通配符(*)一次性为所有用户代理制定搜索蜘蛛抓取规则。
下面来给大家举个例子,如果你想屏蔽所有的搜索蜘蛛,可参考以下robots.txt文件写法:
User-agent: *
Disallow: /
User-agent: Googlebot
Allow: /
在网站robots.txt文件中,你可以指定多个用户代理,每指定一个新的用户代理,它都是独立的,简单地讲如果你在robots.txt文件中为多个用户制定规则,那么第一个用户代理规则并不适用于第二个,第二个并不适用于第三个,依此类推。
需要注意的是,如果你为同个用户代理制定了多次规则,那么这些规则将会被放在一起执行。
重要提示:
搜索蜘蛛只会遵守表述准确且详细的用户代理指令,因此上面的robots.txt文件会禁止除谷歌蜘蛛外所有搜索蜘蛛的抓取,谷歌搜索蜘蛛会忽略一些不太准确详细的用户指令声明。
Directives(指令)
robots.txt文件指令指的是你希望搜索蜘蛛遵循的规则。
目前支持的指令
下面是目前谷歌蜘蛛支持的robots指令及谷歌搜索的用法。
Disallow指令
使用此robots指令可以禁止搜索蜘蛛访问某个文件或页面,例如你想禁止搜索蜘蛛访问你的博客目录及博客帖子页面,则robots.txt文件就可以像下面这样写:
User-agent: *
Disallow: /blog
注意:如果你在robots.txt文件的Disallow指令后没有写任何路径,则搜索蜘蛛就会忽视它。
Allow指令
使用此Allow指令是规定搜索蜘蛛访问网站某个文件或者页面,即使被disallow指令屏蔽了仍然可以使用,如果你屏蔽特定文章以外的所有网站页面,那么robots.txt文件就可以这样写:
User-agent: *
Disallow: /blog
Allow: /blog/allowed-post
在以上这个robots.txt文件规则中,是允许搜索蜘蛛抓取/blog/allowed-post这个目录的,但不允许搜索蜘蛛抓取
/blog/another-post、/blog/yet-another-post、/blog/download-me.pdf这些目录,谷歌和百度搜索都是支持此指令的。
注意:和Disallow指令一样,如果你在allow指令没有加任何路径,那么搜索蜘蛛也会忽略它。
robots.txt文件规则说明:
编写robots.txt文件规则需要非常细心,否则disallow指令与allow指令冲突了你都不知道,如下方所示,我们在robots.txt文件中阻止了搜索蜘蛛抓取/blog/这个目录,但同时也开放了/blog这个目录的抓取。
User-agent: *
Disallow: /blog/
Allow: /blog
在以上这个robots.txt文件中/blog/post-title/这个目录被禁止抓取了,但Allow: /blog
这段以开放了/blog
目录的抓取,那么搜索蜘蛛到底执行哪个指令呢?
谷歌和必应搜索一般会执行较长那个指令,在以上这个例子中会执行disallow指令。
Disallow: /blog/ (6 字符)
Allow: /blog (5 字符)
在以上这个例子中,disallow和allow指令长度是一样的,那么限制较小的范围就会被执行,以上这个例子会执行Allow指令。
提示:由于Allow: /blog中/blog后面没有斜杠,则是被认为可以抓取的,严格来说只适用于谷歌搜索和必应搜索,其它的搜索会执行第一条指令,也就是会执行disallow指令。
Sitemap指令
使用sitemap指令可标记网站地图文件,如果你对网站xml地图还不是特别熟悉,sitemap网站地图文件包含了该网站可被搜索蜘蛛抓取索引的所有网站页面链接。
以下就是某个网站robots.txt文件中Sitemap指令:
Sitemap: https://www.zhuzhouren.cn/sitemap.xml
User-agent: *
Disallow: /blog/
Allow: /blog/post-title/
网站robots.txt文件中标明了sitemap指令的重要性,如果你已向搜索站长平台提交了网站地图文件,那么这个步骤就可以省略掉,对于其它搜索平台,例如必应搜索,就需要明确标明网站地图文件在什么位置,这个步骤是非常重要的,这里我们需要注意的是不需要针对不同代表用户标注不同的sitemap指令,所以我们只需要将sitemap指令标注在robots.txt文件在最开始或最末尾处,如以下这样:
Sitemap: https://www.zhuzhouren.cn/sitemap.xml
User-agent: Googlebot
Disallow: /blog/
Allow: /blog/post-title/
User-agent: Bingbot
Disallow: /services/
谷歌搜索、百度搜索、Ask、必应、雅虎搜索都支持sitemap指令,你也可以在robots.txt文件中写多条sitemap指令。
不再支持的指令
下面是谷歌搜索不支持的指令,由于技术原因这部分指令一直没有被支持过。
Crawl-delay指令
可用这个指令来指定搜索蜘蛛抓取的间隔时间(秒),例如你希望搜索蜘蛛在每次抓取网站页面后等待5秒钟,那以你就可以这样写,如下所示:
User-agent: Googlebot
Crawl-delay: 5
谷歌搜索不支持以上这个指令,但必应和Yandex搜索是支持此指令的。
注意你在设置这个指令的时候要特别小心,特别是大中型网站,否则会限制网站页面抓取,例如你将Crawl-delay指令设置为5,那么搜索蜘蛛只能抓取你网站17,280个网站页面,如果你的网站大型网站,那么这个抓取量是非常小的,如果你的网站为小型网站,则不需要管,还可以帮你的网站省流量带宽。
Noindex指令
noindex指令从来就没有被谷歌搜索支持过,近年来,有些人认为谷歌有一些“处理不受支持和未发布的规则的代码(例如noindex)”,所以如果你想阻止谷歌搜索抓取你的网站某个目录页面,你可以使用此指令:
User-agent: Googlebot
Noindex: /blog/
在2019年9月1日,谷歌搜索就表示不支持此指令,但如果你想禁止搜索蜘蛛抓取某个目录页面的话,你可以使用meta robots标签或x-robots HTTP头部指令。
Nofollow指令
nofollow指令谷歌搜索也从来没有支持过,这个标签谷歌搜索以前是用来阻止搜索蜘蛛抓取另一个链接的,例如你想禁止谷歌搜索抓取你的博客目录页面,你就可以这样设置:
User-agent: Googlebot
Nofollow: /blog/
谷歌搜索在2019年9月1表示说不支持这个robots指令,如果你想禁止搜索蜘蛛抓取此页面上的所有链接,你可以使用meta robots标签或x-robots HTTP头部指令,如果你想让谷歌搜索不追踪某个链接,那么你可以在这个url超级链接中加入rel=”nofollow”参数,加入了这个参数,搜索蜘蛛就不会追踪这个链接了。
你需要一个Robots.txt文件吗?
对于有些网站来说,有无robots.txt文件无所谓,特别是一些小网站,虽然有没有robots.txt文件都差不多,但却没有理由不去拥有它,因为网冰点robots.txt文件可以控制搜索蜘蛛哪些网站文件或目录可以抓取,哪些不可以抓取,网站robots.txt文件作用主要有以下几个:
1、防止搜索蜘蛛抓取收录重复页面;
2、禁止网站在某个阶段不被搜索蜘蛛抓取;
3、禁止搜索蜘蛛抓取网站某个文件或目录;
4、防止网页服务器过载;
5、防止网页浪费了搜索蜘蛛抓取预算;
5、防止用户隐私被抓取。
百度或谷歌搜索一般不会抓取robots.txt文件所禁止的内容,但没有办法保证robots.txt文件禁止的内容就一定不会被搜索蜘蛛抓取,例如,谷歌搜索曾经就表示过,如果搜索蜘蛛从另外途径获得了robots.txt文件禁止页面内容链接,那么就有可能将robots.txt文件禁止的内容展现在搜索结果中。
如何找到你的robots.txt文件?
网站robots.txt文件直接存储在网站根目录中,例如通过域名.com//robots.txt就可以直接访问网站robots.txt文件,看到下图中类似的信息,这个就是网站robots.txt文件内容。

如何建立一个robots.txt文件?
如果你网站没有robots.txt文件,想要新建一个robots.txt文件,其实也是非常简单的,首先新建一个.txt文件,然后按照要求填写如下robots指令,例如你不希望搜索蜘蛛抓取/admin/这个目录,就可以像以下这样进行设置:
User-agent: *
Disallow: /admin/
你还可以继续添加robots指令,只到满足你的要求为止,然后将文件保存为robots.txt,为了避免robots文件语法错误,建议使用百度站工具对robots.txt文件进行校验,如下图所示:
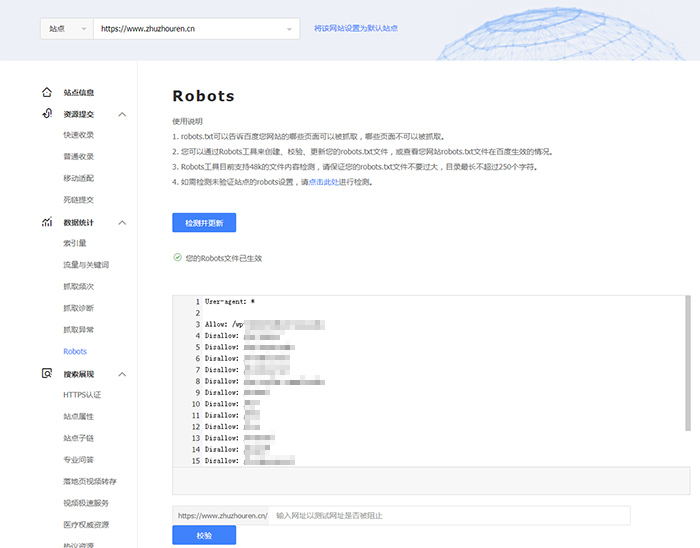
此步骤非常重要,可以避免由于robots文件语法错误给网站带去严重的后果。
在哪里放置robots.txt文件呢?
将robots.txt文件放在网站根目录中,例如你的网站域名为zhuzhouren.cn,那么robots.txt文件就可以用zhuzhouren.cn/robots.txt这个url地址访问到。
如果你的网站域名为二级域名,例如blog.zhuzhouren.cn,那么robots.txt就可能通过blog.zhuzhouren.cn/robots.txt进行访问。
Robots.txt的写法
每一个新指令都需要另起一行
每一个robots指令都占据一行,否则会让搜索蜘蛛理解错误:
错误示例:
User-agent: * Disallow: /directory/ Disallow: /another-directory/
标准示例:
User-agent: *
Disallow: /directory/
Disallow: /another-directory/
使用通配符简化指令
我们不但可以使用通配符(*)指令应用于所有用户代理,还可以使用通配符(*)指令来匹配类似的URL地址,例如,你想禁止搜索蜘蛛访问网站参数化url地址,你可以像以下这样进行设置:
User-agent: *
Disallow: /products/t-shirts?
Disallow: /products/hoodies?
Disallow: /products/jackets?
…
但以这种方法太过于复杂,我们可以将其简化成以下这样:
User-agent: *
Disallow: /products/*?
以上这个robots指令代表的意思是禁止所有搜索蜘蛛抓取/product/目录下所有带问号(?)的url链接,简单地讲就是禁止搜索蜘蛛抓取/product/目录下所有带问号(?)的url链接。
使用美元符号($)来标注以特定字符结尾的URL
”$”美元符号是robots指令结尾特定字符,例如你想禁止搜索蜘蛛抓取所有.pdf格式的url链接,那么你的robots.txt文件可以这样进行设置,如下所示:
User-agent: *
Disallow: /*.pdf$
以上robots文件指令代表的意思是禁止搜索蜘蛛抓取任何以.pdf为结尾的url链接,例如无法抓取/file.pdf这样的文件,但可以抓取/file.pdf?id=68937586,因为这个文件不是以.pdf结尾的。
相同的用户代理只声明一次
如果你在robots文件中多次声明了相同的用户代理,谷歌搜索虽然没有表示说反对这样的申明,但却是可以在一起执行的,如下所示:
User-agent: Googlebot
Disallow: /a/
User-agent: Googlebot
Disallow: /b/
谷歌蜘蛛不会索引以上robots文件指令中的任何一个目录。
虽然谷歌搜索没有表示说不能这么做,但却为了不给搜索蜘蛛困惑,建议只声明一次就行了。
使用精准的指令避免以外的错误
如果你使用精准的robots文件指令,很有可能会给网站优化带去很严重的错误,例如下方robots.txt文件指令本意是只禁止搜索蜘蛛抓取/de/目录中的内容:
User-agent: *
Disallow: /de
但是这个robots.txt文件指令同时也禁止了搜索蜘蛛抓取以/de开头的目录内容,如下方所示:
/designer-dresses/
/delivery-information.html
/depeche-mode/t-shirts/
/definitely-not-for-public-viewing.pdf
以上这种问题我们只需要多加一个斜杠就行了,如下方所示:
User-agent: *
Disallow: /de/
使用注释给开发者提供说明
注释功能可以向开发者说明robots.txt文件指令的作用,如下方所示:
# This instructs Bing not to crawl our site.
User-agent: Bingbot
Disallow: /
搜索蜘蛛会忽略所有以“#”井号开头的robots.txt文件指令。
针对不同的子域名使用不同的robots.txt文件
robots.txt文件只限于当前根目录域名所使用,如果你需要设置其它的域名的robots.txt文件规则,那么就需要设置多个robots.txt文件规则。
例如,当前主站域名为www.zhuzhouren.cn,而你的博客二级域名为blog.zhuzhouren.cn,那么这种情况就需要设置多个robots.txt文件,一个放在主站根目录下,一个放在博客网站根目录下。
Robots.txt文件示例
下面的robots.txt文件示例,主要是给站长们一些参考,如果这些robots.txt文件指令正好与你要求一样,那么你可以将以下robots指令复制粘贴到txt文件中,将其另存为robots.txt文件上传至网站根目录中。
以上robots指令代表的意思是允许所有搜索蜘蛛访问网站所有页面:
User-agent: *
不允许任何搜索蜘蛛抓取网站任何页面
User-agent: *
Disallow: /
禁止所有搜索蜘蛛抓取/folder/这个目录。
User-agent: *
Disallow: /folder/
禁止所有搜索蜘蛛抓取/folder/这个目录,但保留/folder/目录下page.html这个页面可以抓取。
User-agent: *
Disallow: /folder/
Allow: /folder/page.html
禁止所有搜索蜘蛛抓取this-is-a-file.pdf这个文件
User-agent: *
Disallow: /this-is-a-file.pdf
禁止所有搜索蜘蛛抓取网站pdf文件
User-agent: *
Disallow: /*.pdf$
禁止谷歌蜘蛛抓取带参数的url页面。
User-agent: Googlebot
Disallow: /*?
如何检测robots.txt文件中的问题?
robots.txt文件是非常容易出错的,所以对robots.txt文件的校验也是非常有必要的,下面大兵来给大家讲讲robots.txt文件常见错误,包括robots文件指令的含义及解决办法:
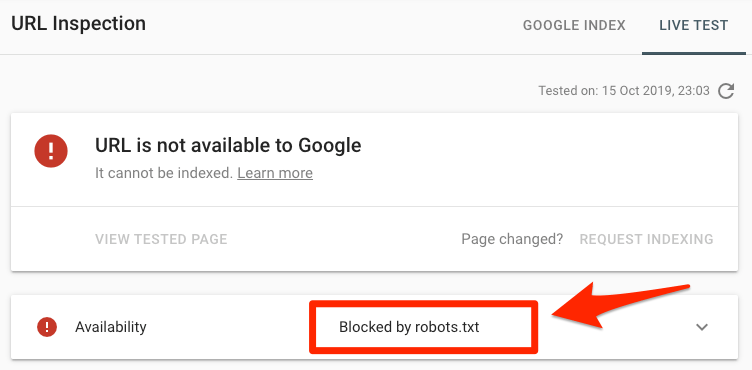
检验网站某个目录页面是否有错误,你可以将robots.txt文件中屏蔽的目录或文件放入Search Console(谷歌资源管理器)的URL Inspection tool(网址检测),如果显示被robots.txt文件屏蔽了,就如下方所示:
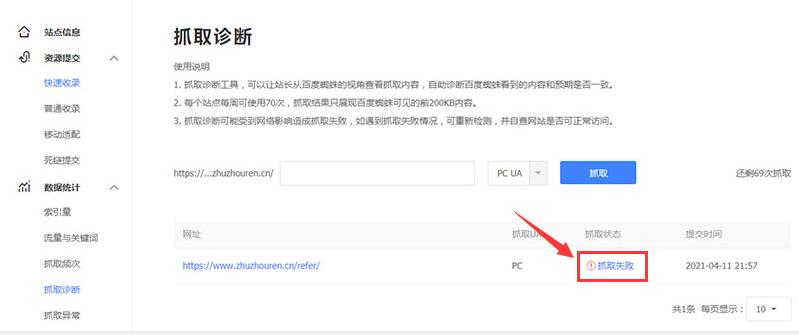
国内用户使用百度站长平台也可以进行检测,如下图所示:
显示该目录被robots.txt屏蔽了,如下图所示:
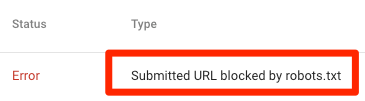
上图中意味着此链接在Sitemap文件当中,至少有一条url链接被robots.txt屏蔽了。
如果你的网站地图sitemap文件是正确的,页面中并不包含canonicalized、noindexed、redirected等标签,而且你所提交的sitemap文件链接没有被robots.txt屏蔽,如果检测这个页面链接确实被屏蔽了,那么就需要检查被屏蔽的页面,再调整robots.txt文件,删除相应的robots指令。
检测网站目录有没有被屏蔽,你可以使用谷歌的robots.txt检测工具和百度站长平台robots文件检测工具来检测robots指令,在修改robots指令的时候也需要特别小心,因为你的修改会影响网站其它目录页面或文件。
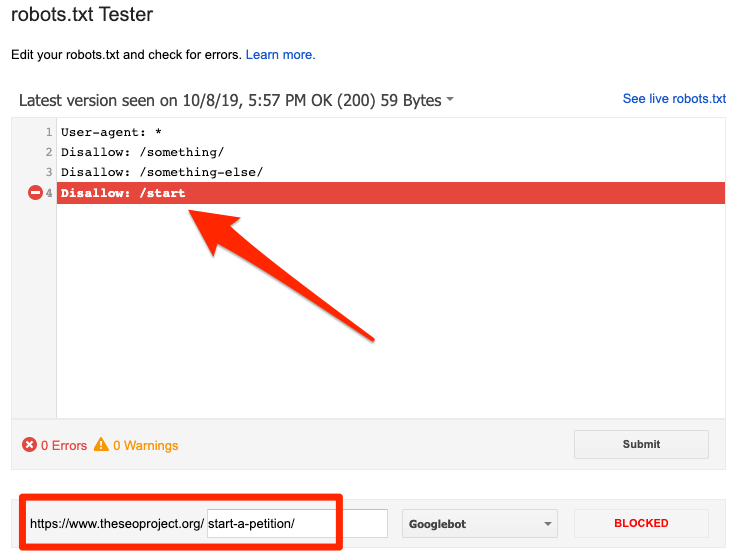
从上图中可以看出带有start的网站目录都被robots.txt屏蔽了
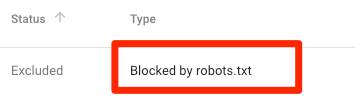
上图中代表的意思是带有start的网站内容都被robots.txt屏蔽了,暂时屏蔽了谷歌蜘蛛索引。
被robots指令禁止索引的内容是需要被搜索蜘蛛抓取的内容,那么我们只需要删除错误的robots指令即可,此时你需要注意此内容是否被robots文件标记为禁止索引状态,如果禁止索引的内容是不需要被索引的内容,那么就可以删除屏蔽索引指令,然后使用meta robots标签、x-robots HTTP头部指令进行屏蔽,保证此页面内容不被搜索蜘蛛索引。
注意,如果你想将被屏蔽抓取的内容从禁止索引库中删除,首先必须要删除抓取阻碍,否则搜索蜘蛛是无法抓取页面内容的。
索引但是被robots.txt屏蔽
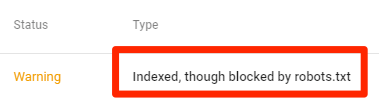
这表示虽然有部分内容被robots.txt文件屏蔽了,但仍然可以被谷歌索引。
如果你希望从搜索引擎索引库中删除该内容,robots.txt文件指令并不是最好的办法,可使用meta robots标签、或者是x-robots HTTP头部指令防止页面被搜索蜘蛛索引。
如果你是不小心将该内容屏蔽了,并且希望该内容重新被搜索引擎索引,只需要在robots.txt文件中删除相关指令就行了,这样就可以让该内容展示在搜索引擎中了。
FAQs
以下是站长朋友们经常问的问题,如果下方问题并没有包含你所需要解答的问题,欢迎大家在下方评论区别留下你的问题,大兵会及时给大家解答。
1)robots.txt文件大小最大为多少?
约为500 千字节。
2)WordPress中的robots.txt在哪里?
robots.tx文件在网站根目录下,例: 域名.com/robots.txt.
3)如何在Wordpress当中编辑robots.txt?
你可以手动编辑该文件,也可以使用WordPress相关插件编辑robots.txt文件,直接在WordPress后台就可以编辑。
4)如果robots.txt文件屏蔽了不想被禁止索引的页面有哪些影响?
robots.txt文件屏蔽了不想被禁止索引的页面的影响,要看屏蔽时间的长短,时间长则影响大,时间短则影响小,最后我们只需要改正错误的robots指令即可。
5)noindex标记谷歌搜索是否可以识别?
谷歌搜索虽然没有明确表示可以识别此标签,但如果此页面你不想被搜索蜘蛛索引,你可以将noindex标签放在页面中,这样谷歌识别出了这个标记,就不会收录该页面。
最后的想法
robots.txt文件虽然看上去简单,但却是最容易出错的,一旦出错对网站SEO优化的影响将是非常严重的,甚至造成这个网站直接废掉。
免责声明:本文所有图片、视频、音频等资料均来自互联网,不代表本站赞同其观点,内容仅提供用户参考,若因此产生任何纠纷,本站概不负责,如有侵权联系本站删除!邮箱:452315957@qq.com
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 









评论列表(1条)
[…] robots文件对网站优化非常重要,因此,每个网站必须制作一个与网站具体情况相符合的robots规则文件,这样不但可以提升蜘蛛的抓取效率,还可以告诉蜘蛛网站哪些目录可以抓取,哪些目录不可以抓取,总的来说,对于网站优化是非常有利的。这是robots文件的具体用法,可参见:https://www.zhuzhouren.cn/seojishu/4608.html […]