robots标签是什么意思?
robots标签是什么意思?
robots标签是网站与搜索引擎蜘蛛之间一种协议,文件内容主要是告诉搜索蜘蛛网站哪些页面可以抓取,哪些页面是禁止抓取的,简单地讲robots标签文件是搜索引擎蜘蛛访问网站第一个要看的文件,当搜索蜘蛛访问网站的时候,首先会检查robots.txt文件有没有在网站根目录中,如果此文件在网站根目录中,那么搜索蜘蛛就会根据此文件的规则来抓取网站页面内容,如果网站根目录没有此文件,那么搜索蜘蛛默认网站上所有页面都是可以抓取的。

robots标签索引控制参数:
noindex:是告诉搜索蜘蛛此页面禁止抓取索引;
index:告诉搜索蜘蛛此页面可以被抓取收录;
follow:告诉搜索引擎此页面上所有链接都可进行索引,也可以进行权重传递。
nofollow:此标签是提示搜索蜘蛛不要抓取此页面的任何链接,也不要进行权重传递;
noimageindex:提示搜索蜘蛛不要抓取此网页上的任何图片;
none:与noindex和nofollow标签作用相同;
noarchive:告诉搜索引擎不要在搜索结果中显示指向此页面的缓存链接;
nocache:与noarchive标签作用相同,仅由Internet Explorer和Firefox使用;
nosnippet:告诉搜索蜘蛛不要在搜索结果中显示此页面的描述;
noodyp / noydir [OBSOLETE]:禁上在搜索结果中使用该页面的描述内容作为该页面的搜索引擎结果,DMOZ标签已于2017年失效;
Unavailable_after:在某个特定日期后,搜索蜘蛛不再为该页面显示索引内容;
meta robots 标签的作用:
1、<meta name=”robots”content=”noindex, nofollow” />这个标签代表的意思是不想让搜索蜘蛛抓取收录此页面内容,同时还可禁止搜索蜘蛛索引该页面内容,也禁止搜索蜘蛛追踪此页面上的所有链接;
2、<meta name=”robots” content=”noindex, follow” />禁止搜索蜘蛛抓取此页面内容,但允许搜索蜘蛛跟踪此页面链接,也可以传递网站权重值。
meta robots标签许多搜索引擎平台是不支持的,只有少数搜索引擎可以识别,所以大兵还是建议大家使用robots.txt文件来限制搜索蜘蛛抓取网站页面内容。
想要了解robots.txt文件如何编写,可以参考《robots.txt文件要如何正确设置》这篇文章。
robots标签元指令的类型
robots标签元指令分为两个类型,分别为robots元标签和x-robots-tag,可在meta robots标记中使用任意参数,也可在x-robots-tag中进行指定。
大兵将在下面详细讲解meta robots和x-robots标签指令。
meta robots标签
meta robots标记,一般也可称为meta robots或robots标记,都是属于html代码的一部分,显示在<head></head>代码元素中。
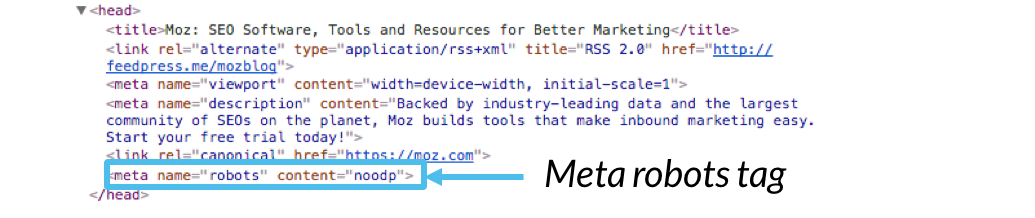
代码示例:
<meta name=”robots” content=”[参数]”>
虽然<meta name=”robots” content=”[PARAMETER]”>标签是常规标签,也可以通过robots标签替换成某个特定用户向某个特定搜索蜘蛛传达抓取指令,例如要对Googlebot谷歌搜索蜘蛛,可使用以下代码:
<meta name =“ googlebot” content =“ [DIRECTIVE]”>
是否需要传达多个指令,只针对一个robots,多个抓取指令都可以包含在meta标签指令中,用英文逗号隔开即可,如下所示:
<meta name =“ robots” content =“ noimageindex,nofollow,nosnippet”>
以上robots标记是告诉搜索引擎不要抓取此页面上的任何图像,也不要跟踪此页面上的任何链接或显示任何搜索结果页面。
如果你需要针对不同搜索蜘蛛使用不同的meta robots标签指令,只需要为每个robots使用单独的标签即可。
X-robots-tag标签
虽然meta robots标签允许你在此页面控制搜索蜘蛛的抓取行为,但x-robots-tag可作为网页HTTP标头的一部分控制整个网页特定元素的索引。
尽管你可以使用x-robots-tag和meta robots标签来执行相同的索引指令,但x-robots-tag指令比meta robots标记更灵活,功能更多,x-robots-tag可允许使用正则表达式,可在非html页面中执行索引指令及全局级别应用参数。
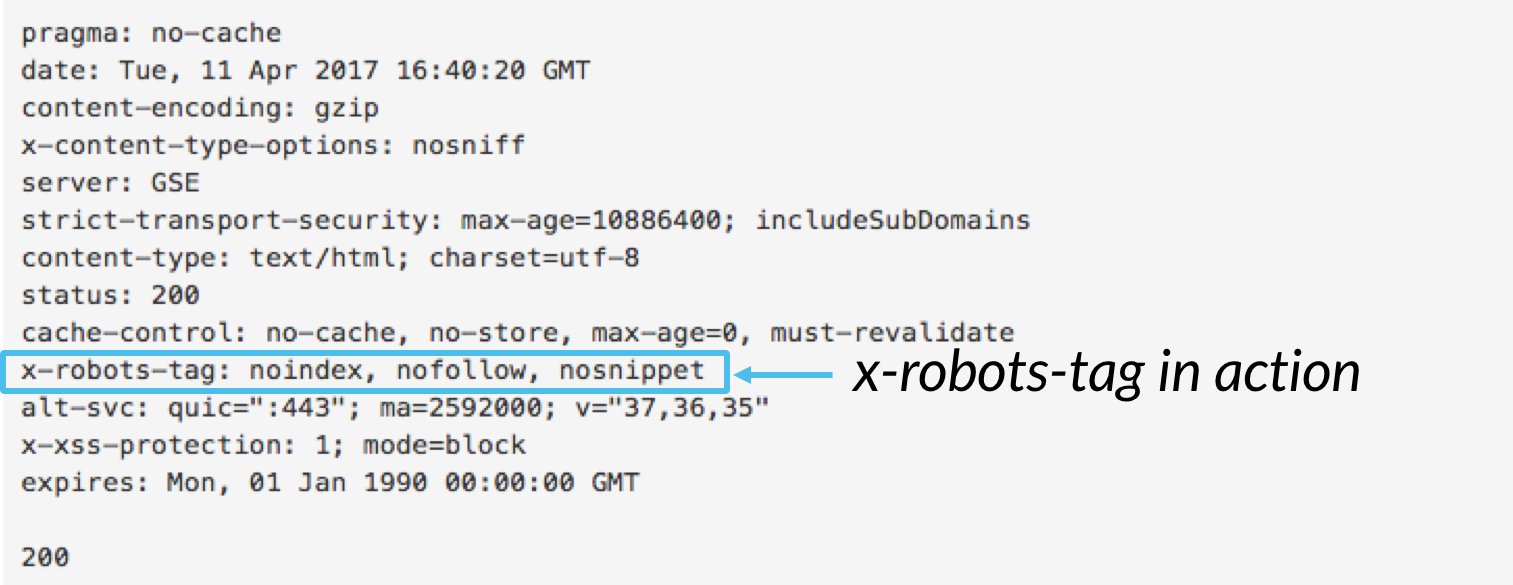
想要使用x-robots-tag标记,你需要用到header.php、.htaccess文件,然后再添加特定服务器配置的x-robots-tag标记,包含任何参数设置,下面给大家提供一个很好的例子,一起来看看。
以下是x-robots-tag的使用实例:
控制非html内容索引编制(例如Flash、视频内容),阻止网页特定元素,例如图像、视频等索引编制,但不阻止整个网页的索引编制,如无权访问整个网页html代码,尤其是网页head部分,或者你无权更改网页header,则控制网页索引编制为是否应为页面建立索引添加规则(例如,如果用户发表了20次以上评论,则为其用户页面建立索引)。
使用robots文件指令的SEO实践
当搜索蜘蛛抓取某些页面时,首先看到为robots文件,如果网站robots.txt文件禁止搜索蜘蛛抓取某些网站目录页面,则该页面上的所有meta指令都将忽略。
一般情况下,应使用带有参数noindex、follow的meta robots标记作为限制搜索蜘蛛索引的方法,而不是直接使用robots.txt文件禁止抓取网站某个目录页面。
这里我们需要注意的是,有些搜索引擎蜘蛛会直接忽视robots文件指令,所以robots文件协议也不能提百分百的搜索机制,如果你不想公开网站某个页面的信息,建议使用密码进行加密,防止泄漏了。
不建议在同一个网页上同时使用meta robots和x-robots-tag标签,因为这是多余的。

